Scaling a local business through organic search is a notoriously difficult engineering challenge. The traditional approach—manually crafting hundreds of "Service + City" pages using a monolithic CMS like WordPress—is expensive, prone to human error, and architecturally brittle. Furthermore, when executed poorly, mass page generation inevitably triggers Google’s duplicate content filters, leading to keyword cannibalization, indexation bloat, and algorithmic penalties.
In 2026, the strategy has evolved. Programmatic SEO (pSEO) leverages massive datasets, dynamic templates, and Static Site Generation (SSG) to deploy thousands of hyper-relevant local landing pages instantly. This guide details the technical frameworks required to scale local SEO programmatically for enterprise applications (500 to 50,000+ pages) while strictly avoiding keyword cannibalization and thin content penalties.
The Threat Vector: Keyword Cannibalization and Thin Content
Keyword cannibalization occurs when multiple pages on your domain compete for the exact same search intent. In programmatic SEO, this typically manifests when an engineering team generates pages for overlapping jurisdictions, such as a localized page for "Miami Plumber" and another for "Miami-Dade County Plumber," using the exact same underlying template and identical boilerplate text.
When Google encounters thousands of pages where only the city name has been string-replaced (often called "Mad Libs SEO" or "spin-text"), its algorithms classify the cluster as doorway pages or thin content. The result is a total collapse in crawl priority, widespread de-indexation, and severe traffic losses during Google Core Updates. Google's Natural Language Processing (NLP) models are highly adept at identifying structural and semantic repetition across a domain.
Architectural Defense Mechanisms
To bypass these filters, your programmatic architecture must guarantee high content variance and strict intent separation. You cannot simply spin text; you must inject unique data variables that provide localized, tangible value that a user could not easily find elsewhere.
Constructing the Localized Data Model
The foundation of a successful programmatic SEO campaign is the database. Instead of relying on static markdown files with minor variations, you must build a relational data model that aggregates localized data points across multiple independent APIs.
Consider a pest control company scaling across Texas. A superior data schema for a city page would include:
- Geographic Coordinates: Exact latitude and longitude for localized Schema.org markup.
- Climate Data Integration: Integrating an API to pull local humidity and temperature averages, tying them to pest activity (e.g., "Houston's 80% average humidity accelerates subterranean termite swarm rates.").
- Local Demographics: Housing age statistics (e.g., "With 40% of homes in Austin built before 1990, rodent exclusion requires specific architectural retrofitting that modern homes bypass.").
- Dynamic Review Aggregation: Pulling localized Google Business Profile (GBP) reviews specific to that exact zip code or municipality.
- Proximity Calculations: Dynamically calculating the driving distance and estimated arrival times from the nearest physical service hub.
Example: Next.js Dynamic Route with Data Blending
Using Next.js, we can utilize generateStaticParams to build these pages at compile time, ensuring absolute performance while blending diverse datasets. The build step acts as a data pipeline, ingesting JSON feeds and outputting highly customized HTML documents.
// app/service/[city]/page.tsx
import { getCityData, getWeatherContext, getLocalReviews, getDistanceMatrix } from '@/lib/api';
import { notFound } from 'next/navigation';
export async function generateStaticParams() {
const cities = await getCityData();
return cities.map((city) => ({
city: city.slug,
}));
}
export default async function CityServicePage({ params }) {
const cityData = await getCityData(params.city);
if (!cityData) return notFound();
// Parallel data fetching for high performance build times
const [weatherContext, reviews, logistics] = await Promise.all([
getWeatherContext(cityData.lat, cityData.lng),
getLocalReviews(cityData.placeId),
getDistanceMatrix(cityData.zipCode)
]);
return (
<article className="local-service-layout">
<header>
<h1>Pest Control Services in {cityData.name}, {cityData.state}</h1>
</header>
<section className="localized-context">
<h2>Why {cityData.name}'s Climate Demands Specialized Control</h2>
<p>
Given the average summer humidity of {weatherContext.humidity}% and
historical rainfall patterns, subterranean termites are highly active in the {cityData.region} corridor.
</p>
</section>
<section className="logistics">
<h2>Service Availability</h2>
<p>Our nearest dispatch center is {logistics.distanceMiles} miles away,
allowing for an estimated response time of {logistics.etaMinutes} minutes
to any address in {cityData.name}.</p>
</section>
<section className="dynamic-reviews">
{/* Render highly specific local reviews */}
<LocalReviewCarousel reviews={reviews} />
</section>
</article>
);
}
By aggregating multiple data sources, the generated HTML for "Houston" will be fundamentally structurally and linguistically different from the HTML generated for "Dallas," completely negating the duplicate content penalty.
Resolving Cannibalization via URL Architecture and Canonicalization
When targeting large metropolitan areas, businesses often service dozens of micro-neighborhoods (e.g., targeting "Brooklyn," "Williamsburg," and "Bushwick"). If not structured correctly, these pages will cannibalize each other for the core "NYC" or "Brooklyn" terms.
The Hub and Spoke Architecture
Implement a strict hierarchy using internal linking, semantic HTML, and breadcrumbs. This signals to Google exactly how geographical relationships function within your domain.
- State Hub:
/locations/new-york/(Targets: New York Pest Control) - City Hub:
/locations/new-york/brooklyn/(Targets: Brooklyn Pest Control) - Neighborhood Spokes:
/locations/new-york/brooklyn/williamsburg/(Targets: Williamsburg Pest Control)
Internal Linking Rules for Cannibalization Prevention:
- Spoke pages (Williamsburg) must always link up to their direct parent Hub (Brooklyn) using exact match anchor text in a prominent position (e.g., breadcrumbs or introduction).
- Sibling spoke pages (Williamsburg and Bushwick) should link to each other only when geographically adjacent, providing contextual relevance to the user rather than purely algorithmic link sharing.
- The parent Hub must contain a dynamic grid linking to all active spoke pages to distribute PageRank efficiently downwards through the architecture.
Aggressive Canonicalization for Search Intent Overlap
If you determine that the search intent for "Williamsburg Pest Control" and "Greenpoint Pest Control" yield identical SERPs (meaning Google treats them as the same macro intent), you must consolidate them. Having both live will dilute your authority and result in neither ranking on page one.
Instead of deleting the pages (which breaks local user experience), utilize dynamic canonical tags. If the data shows Williamsburg is the primary search volume driver, set the canonical tag on the Greenpoint page to point to Williamsburg, or roll them both up to the Brooklyn hub.
// Injecting dynamic canonicals in Next.js metadata
export async function generateMetadata({ params }) {
const cityData = await getCityData(params.city);
// If this is a micro-neighborhood, canonicalize to the parent city to prevent cannibalization
const canonicalUrl = cityData.isMicroNeighborhood
? `https://www.example.com/locations/${cityData.stateSlug}/${cityData.parentCitySlug}`
: `https://www.example.com/locations/${cityData.stateSlug}/${cityData.slug}`;
return {
title: `Pest Control in ${cityData.name} | Expert Local Service`,
alternates: {
canonical: canonicalUrl,
},
};
}
Advanced Pagination and Faceted Navigation
When scaling to 10,000+ local pages, providing a central directory is crucial for Googlebot discovery. However, standard pagination (?page=2, ?page=3) often results in crawl traps and indexing bloat.
Instead of standard pagination, implement a programmatic faceted navigation system based on alphabetic grouping or regional sub-directories (e.g., /locations/texas/a-to-c/). Ensure that these directory hub pages are heavily optimized for crawl speed and do not rely on client-side JavaScript to render the anchor links.
The SSG Advantage over Legacy Monoliths
Executing this strategy on WordPress requires heavy plugins, custom PHP functions, and massive database queries. Generating 5,000 city pages with dynamic data blending on WordPress will inevitably crash the server during a high-concurrency crawl event or result in TTFB (Time to First Byte) times exceeding 3 seconds. This decimates your crawl budget; Googlebot will abandon the crawl, leaving your newly minted city pages unindexed.
Static Site Generation (SSG) via Next.js solves this entirely. The computationally expensive data fetching, API aggregation, and HTML rendering happens exactly once: at build time within your CI/CD pipeline.
When Googlebot crawls your 5,000 localized pages, it is served pre-compiled HTML directly from a global CDN. The pages load instantly, layout shifts are non-existent, and the server infrastructure scales infinitely without requiring massive MySQL database resources or Redis caching layers.
Automating the Indexing Pipeline
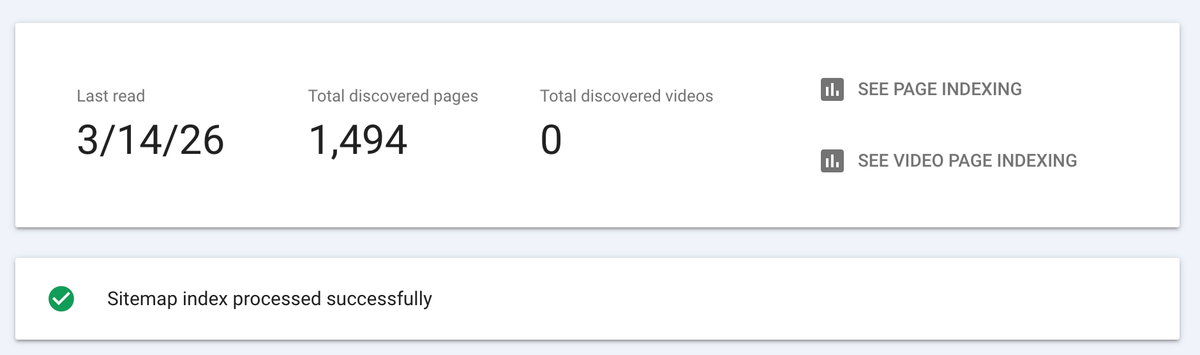
With thousands of programmatic pages, relying on a single XML sitemap is insufficient. You must implement automated, scaled indexing pipelines:
- Sitemap Segmentation: Break your sitemaps into smaller, logically grouped chunks (e.g.,
sitemap-texas.xml,sitemap-florida.xml). Limit each sitemap to 10,000 URLs to ensure Google parses them quickly and you can isolate indexing issues in Google Search Console by region. - Google Indexing API: For high-priority service pages or rapid deployments, wire your CMS deployment webhooks directly to the Google Indexing API. When a new city page is built, automatically send a
URL_UPDATEDpayload to Google, ensuring indexation in minutes rather than waiting weeks for a passive crawl.
Conclusion
Scaling local SEO programmatically requires a paradigm shift from traditional content writing to data engineering. By moving away from legacy monolithic systems, leveraging robust relational data models, and deploying via Static Site Generation, modern engineering teams can capture tens of thousands of local search queries.
The defense against keyword cannibalization and thin content penalties is not writing better copy—it is engineering better data integrations. Build unique, data-rich experiences at scale, strictly control your internal architecture via canonicals and hub-and-spoke models, and dominate the local SERPs with unassailable technical foundations.
Ready to transform your WordPress site?
Get a free preview of your site as a fast, modern site.
Free preview